Towards Self-Supervised Learning of Global and Object-Centric Representations
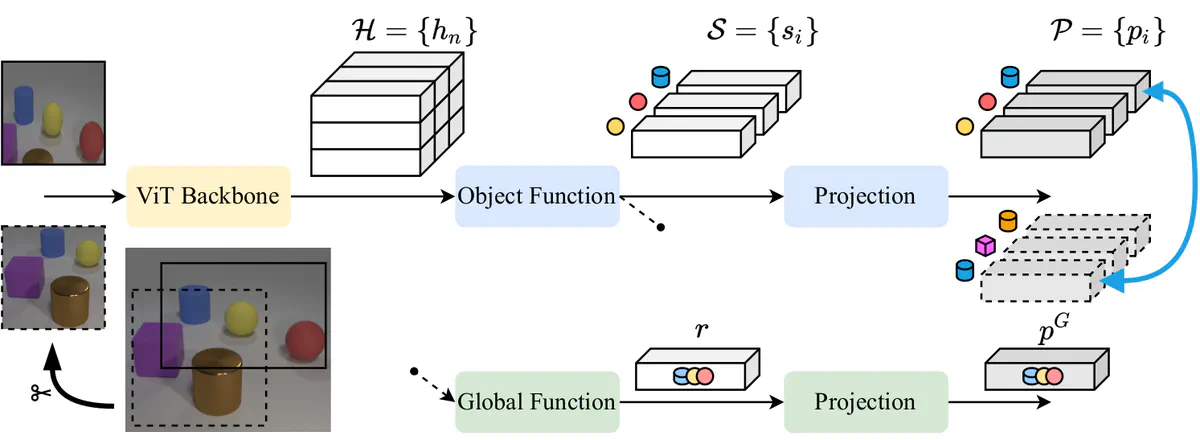 Self-supervised architecture for object discovery with a token-matching contrastive loss.
Self-supervised architecture for object discovery with a token-matching contrastive loss.Abstract
Self-supervision allows learning meaningful representations of natural images, which usually contain one central object. How well does it transfer to multi-entity scenes? We discuss key aspects of learning structured object-centric representations with self-supervision and validate our insights through several experiments on the CLEVR dataset. Regarding the architecture, we confirm the importance of competition for attention-based object discovery, where each image patch is exclusively attended by one object. For training, we show that contrastive losses equipped with matching can be applied directly in a latent space, avoiding pixel-based reconstruction. However, such an optimization objective is sensitive to false negatives (recurring objects) and false positives (matching errors). Careful consideration is thus required around data augmentation and negative sample selection.