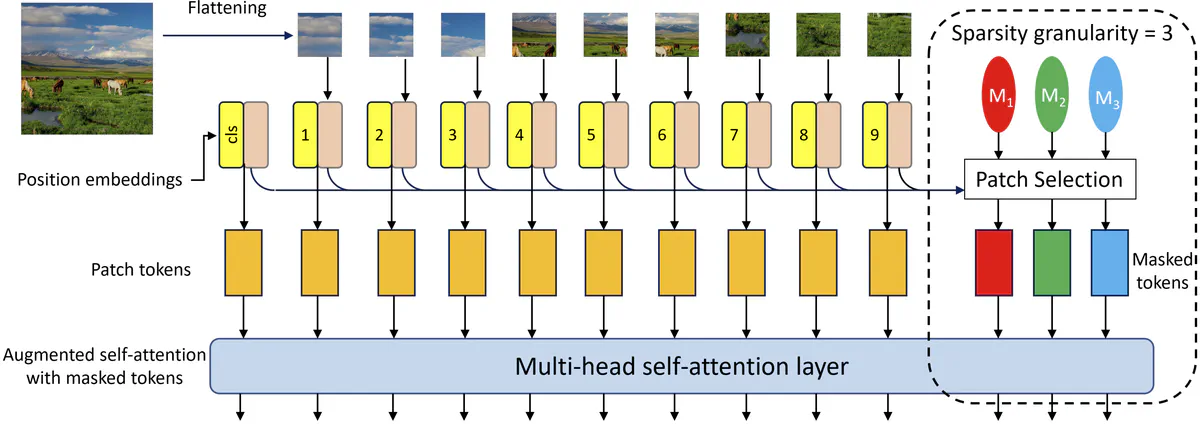
 A vision transformer augmented with the proposed masked tokens.
A vision transformer augmented with the proposed masked tokens.Abstract
Vision transformers have recently shown remarkable performance in various visual recognition tasks specifically for self-supervised representation learning. The key advantage of transformers for self supervised learning, compared to their convolutional counterparts, is the reduced inductive biases that makes transformers amenable to learning rich representations from massive amounts of unlabelled data. On the other hand, this flexibility makes self-supervised vision transformers susceptible to overfitting when fine-tuning them on small labeled target datasets. Therefore, in this work, we make a simple yet effective architectural change by introducing new learnable masked tokens to vision transformers whereby we reduce the effect of overfitting in transfer learning while retaining the desirable flexibility of vision transformers. Through several experiments based on two seminal self-supervised vision transformers, SiT and DINO, and several small target visual recognition tasks, we show consistent and significant improvements in the accuracy of the fine-tuned models across all target tasks.