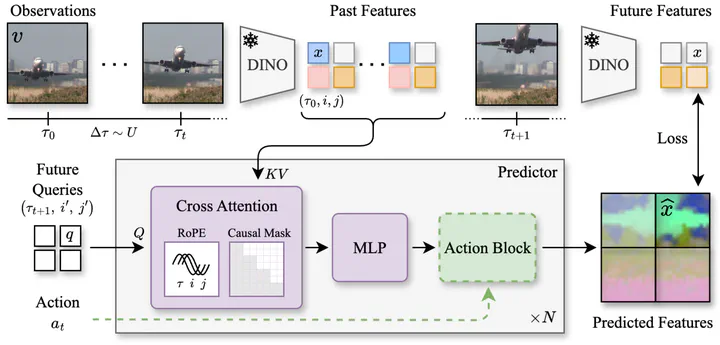
 DINO-world model architecture. Predicting future DINO features given past frames.
DINO-world model architecture. Predicting future DINO features given past frames.Abstract
We present DINO-world, a powerful generalist video world model trained to predict future frames in the latent space of DINOv2. By leveraging a pre-trained image encoder and training a future predictor on a large-scale uncurated video dataset, DINO-world learns the temporal dynamics of diverse scenes, from driving and indoor scenes to simulated environments. We show that DINO-world outperforms previous models on a variety of video prediction benchmarks, e.g. segmentation and depth forecasting, and demonstrates strong understanding of intuitive physics. Furthermore, we show that it is possible to fine-tune the predictor on observation-action trajectories. The resulting action-conditioned world model can be used for planning by simulating candidate trajectories in latent space.
Given past frames, the model can predict future DINOv2 features autoregressively. How well does it do? It depends on the objects in motion and the context provided.
In the video below, the model can observe the taxi trajectory for long enough to predict that it will turn right.

On the contrary, when given a too few frames, the model predicts that the taxi will continue straight. The blurry features towards the end are an artifact of the model’s uncertainty about the future due to the ambiguous context.

An early version of this work, without the action-conditioned fine-tuning and the planning tasks, was presented at the ICML 2025 Workshop on Building Physically Plausible World Models.